


News
2024.07.16
知財ニュース
KDDI、NICTと日本語特化の生成AI開発へ―事実と異なる内容を生成するハルシネーションなどを抑制

KDDIは2024年7月1日、国立研究開発法人情報通信研究機構(NICT)と大規模言語モデル(LLM)に関する共同研究を開始したと発表した。
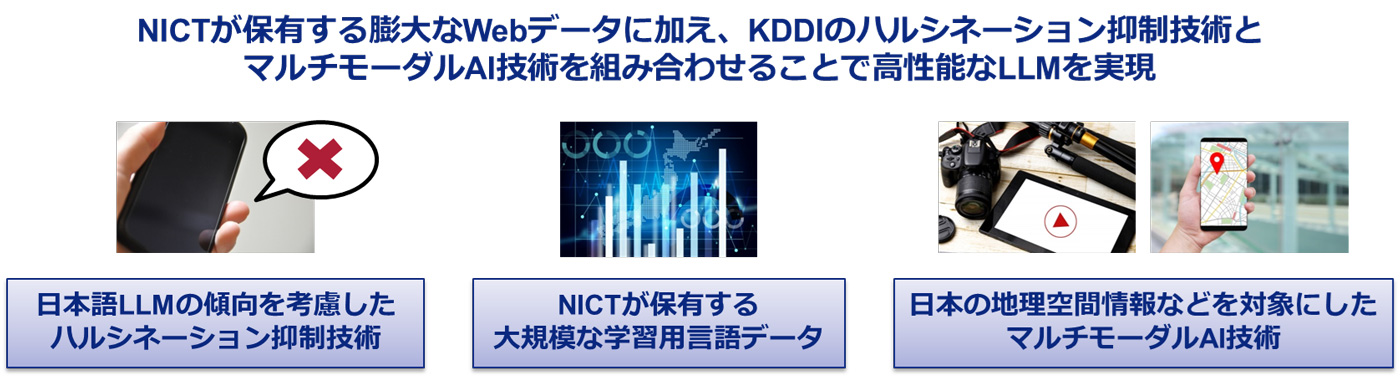
KDDIグループは、生成AI開発のための大規模計算基盤の整備を開始するとともに、オープンモデル活用型の日本語汎用LLMおよび領域特化型LLMの開発体制を整えてきた。NICTは、これまでに蓄積してきた600億件以上のWebページのデータを活用し、LLMの事前学習に用いるデータの整備を進めてきたのだという。
また、並行して軽量な130億パラメータのLLMから日本語特化型では世界最大規模となる3,110億パラメータのLLMまで、1年あまりで合計17個のLLMの事前学習を完了させてきた。
LLMの利用にあたっては、事実と異なる内容や脈絡のない文章などが生成されるハルシネーションや、地図情報の活用が難しいことなどが課題となっている。この研究では、NICTが長年蓄積した膨大なWebページのデータや、そこから作成したLLMの事前学習用データなどを活用し、共同研究を進めていく。
KDDIは、日本語汎用LLMの傾向に合わせたハルシネーション抑制技術の高度化や、地図画像および付随する建物情報などのマルチモーダルデータをLLMで取り扱う技術を、KDDI総合研究所のハルシネーション抑制技術やマルチモーダルAI技術を基に研究開発していくとのこと。
これらの技術により、特定の目的のための対話システムや雑談システムにおける、LLMの信頼性向上につながるとしている。また、LLMによる位置関係の把握などが可能になるため、例えば通信事業者の顧客の応対に適用することで、問題が発生している設備やエリアの迅速な把握が可能となり、通信品質の改善につながることが期待される。
今回開始される研究は総務省・NICTが令和5年度補正予算を活用し推進する「我が国における大規模言語モデル(LLM)の開発力強化に向けたデータの整備・拡充及びリスク対応力強化」における共同研究の第1弾なのだという。
KDDIは、KDDI VISION 2030「『つなぐチカラ』を進化させ、誰もが思いを実現できる社会をつくる。」の実現に向け、NICTを始めとしたさまざまなパートナーと共に、日本独自の生成AI開発を加速させていくとしている。
Top Image : © KDDI 株式会社