


News
2023.02.13
知財ニュース
Meta、テキストから4D(動く3D)を生成できる「Make-A-Video3D」を発表

Metaは2023年1月、テキストから動的な3Dシーンを生成できる「Make-A-Video3D」(MAV3D)を発表した。
「Make-A-Video3D」は、テキスト記述からアニメーションメッシュのダイナミックな3Dシーンを生成できるAI。生成にはNeRF (さまざまな角度から撮影された複数の写真から自由視点画像を生成する技術)の亜種である「HexPlane」の技術を活用し、生成された3Dは、3Dエンジンでリアルタイムにレンダリングできる。
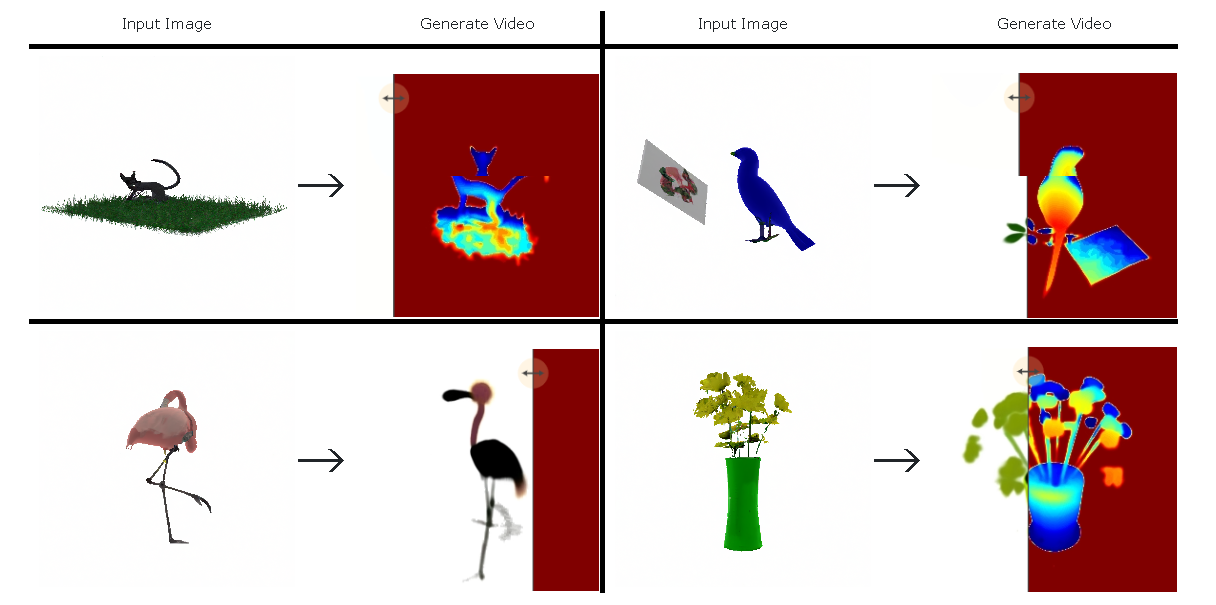
「Make-A-Video 3D」で動く3Dを生成するには、複数視点の写真から生成した画像をMetaの動画生成AI「Make-A-Video」(MAV)にテキストプロンプトとともに入力する。その後MAVはテキストプロンプトやパラメータからこのコンテンツを評価し、学習信号としてスコアを算定、パラメータを調整し、動的な3Dシーンを作成する。なお、Metaによれば、この学習モデルは、大型画像モデル「Imagen」を活用したGoogleのAIモデル「Dreamfusion」と同様のアプローチだという。
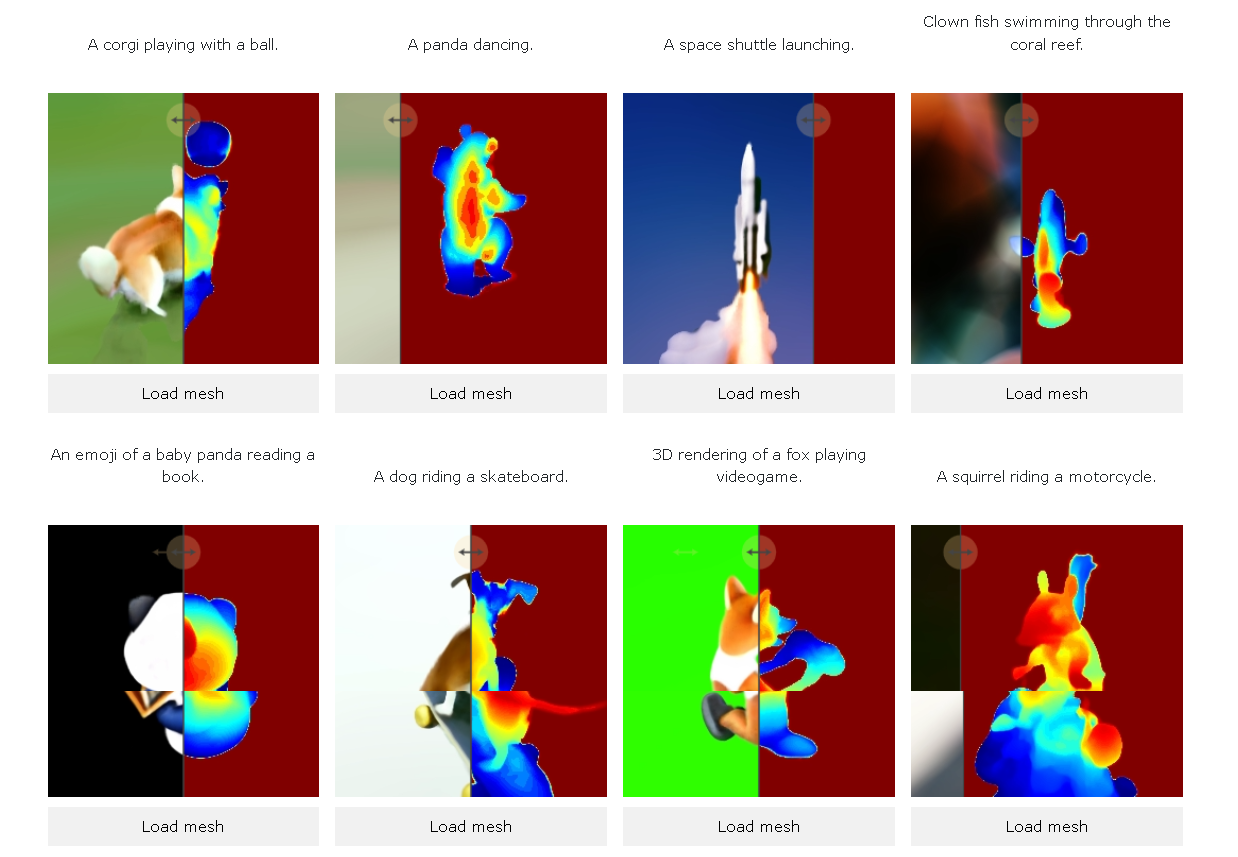
ビデオと3Dを組み合わせたAIの研究開発を推進しているMeta。近年は、Make-A-Videoをはじめとして、Imagen Videoや3DiMなど、動画や3Dオブジェクトを生成できるAIが登場している中、同社の躍進にも今後も期待したい。
「AIでテキストから3D画像を自動生成する手法を米カリフォルニア大学とGoogle Researchらが開発」(ニュース記事)
「米Meta、テキストから動画を生成できるAI「Make-A-Video」を発表」(ニュース記事)
Top Image : © Google Research