


News
2023.09.26
知財ニュース
Stability AI、テキストから音楽を生成するAIモデル「StableAudio」を公開─無料版も提供
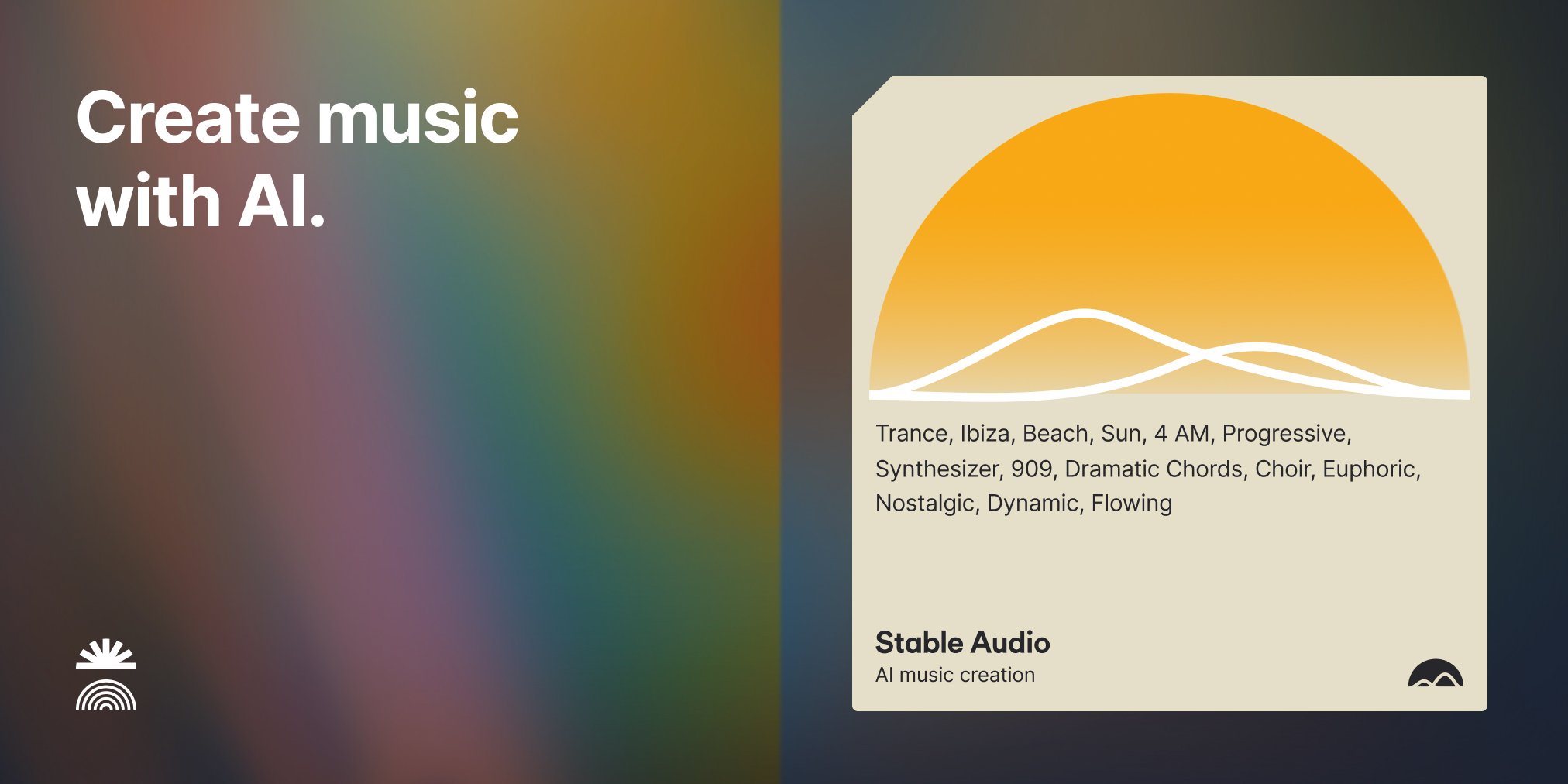
Stability AIは、テキストから音楽を生成する、音楽とサウンド生成のための初のAIモデルとなる「StableAudio」を発表した。
Stable Audioは、最新の生成AI技術と使いやすいWebインターフェースを介して、より高速で高品質な音楽とサウンドエフェクトを提供する世界初の製品。
45秒までのトラックを生成してダウンロードできるStable Audioの基本無料版と、商用プロジェクト用にダウンロード可能な90秒のトラックを提供する「Pro」サブスクリプションを提供する。
オーディオトラックは、ユーザーが提供する説明的なテキストプロンプトと、希望するオーディオの長さに応じて生成される。
例えば、"Post-Rock, Guitars, Drum Kit, Bass, Strings, Euphoric, Up-Lifting, Moody, Flowing, Raw, Epic, Sentimental, 125 BPM" と入力し、95秒のトラックをリクエストすると、次のトラックが生成される仕組み。

Stable Audioの基礎となるモデルは、主要な音楽ライブラリである AudioSparx の音楽とメタデータを使用してトレーニングされている。Stable Audioは、「latent diffusion」 を利用して、商業利用のための高品質な44.1 kHzの音楽を作成できる初の音楽生成製品だ。
latent diffusionアーキテクチャは、テキストメタデータとオーディオファイルの長さと開始時刻を条件とするオーディオを使用し、生成されるオーディオの内容と長さを制御することができる。
StabilityAIのCEOであるEmad Mostaqueは、「唯一の独立した、オープンでマルチモーダルな生成AIの会社として、音楽クリエイターをサポートする製品を開発するために私たちの専門知識を活用できることを嬉しく思う。Stable Audio が音楽愛好家やクリエイティブな専門家にAIの助けを借りて新しいコンテンツを生み出す力を与え、それが無限のイノベーションを生み出すことを期待している」と期待を寄せている。
Top Image : © Stability AI