


News
2025.05.01
知財ニュース
パナソニックHD、未学習の物体も指示できる対話型セグメンテーション技術を開発―テキストと参照画像から学習

パナソニックホールディングスとパナソニックR&Dカンパニーオブアメリカは、カリフォルニア大学バークレー校との共同研究により、言語と参照画像を用いて認識対象を指示できる対話型セグメンテーション技術SegLLMを開発した。
同技術はAI・機械学習分野のトップカンファレンスであるInternational Conference on Learning Representations(ICLR 2025)に採択されている。

セグメンテーションは、画像内の領域を画素レベルで複数の領域に分割する技術。画像認識と組み合わせることで、特定の物体の位置や形状を正確に捉えられ、屋内での物体認識や自動車の周辺環境認識、ロボットによる物体操作など、幅広い応用が期待されている。
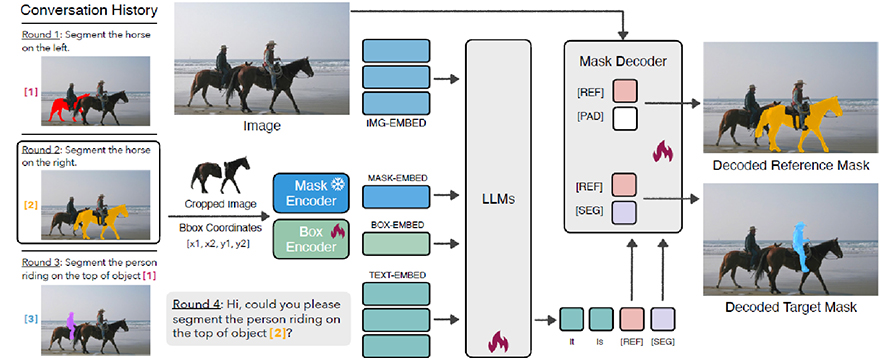
今回開発されたSegLLMは、指示を行う際にテキストだけでなく参照画像も同時に用いることが可能。これにより、まだ学習していない物体であっても、指示文によって物体の階層関係や物体間のインタラクションを認識できる。また、見た目がよく似た物体が多数存在するような複雑な状況下でも、特定の物体だけを正確に認識することができるという。
SegLLMは、テキストと参照画像を同じ特徴空間に埋め込み、LLMに入力する形で学習されている。これにより、過去の対話でLLMが出力したセグメンテーション画像から特定の物体を切り抜き、それを参照画像として次の指示に利用できるため、テキスト入力を長くすることなく、過去の対話内容を踏まえたより的確な指示が可能になる。
また、同研究では、SegLLMの構成だけでなく、対話型セグメンテーションの学習・評価用データセットも新たに提案。このデータセットを用いた実験では、既存の手法が対話を進めるにつれて認識精度が低下するのに対し、SegLLMは精度の劣化を大幅に抑制できたという。
近年、画像認識の分野では、大規模言語モデルを活用し、テキストで認識対象を指示する手法が一般的になっている。しかし、対話形式で指示を行う際、過去の対話で認識した対象を基に新たな指示を出すと、テキストが複雑化し、誤認識が起こりやすいという課題があった。今回の開発は、これまでの課題を解消する一手として期待が集まっている。
今後、パナソニックHDは、SegLLMをFastLabelと共同開発中の自動アノテーションツールに実装を予定しているほか、SegLLMの特性を活かし、CPSへの応用も視野に入れている。パナソニックHDは、今後もAIの社会実装を推進し、顧客の生活や仕事の現場に貢献するAI技術の研究開発に注力していく方針だ。
Top Image : © パナソニックホールディングス 株式会社