


No.068
2020.02.18
画像から瞬時に大量のタグ付けをするソフト
Visual Object Tagging Tool

概要
「VoTT」(Visual Object Tagging Tool)は、対象の画像に対して名前や座標などのメタデータを付ける画像アノテーション技術を持つソフトウェア。従来、メタデータを付けるには沢山の人手と時間が必要だったが、「VoTT」を使うことでこれらを大幅に節約できる。将来的には、画像アノテーション作業を自動化させることで、学習データを自分で作って蓄積し、画像認識や物体検出の精度を向上させるようなAIの実現が期待される。
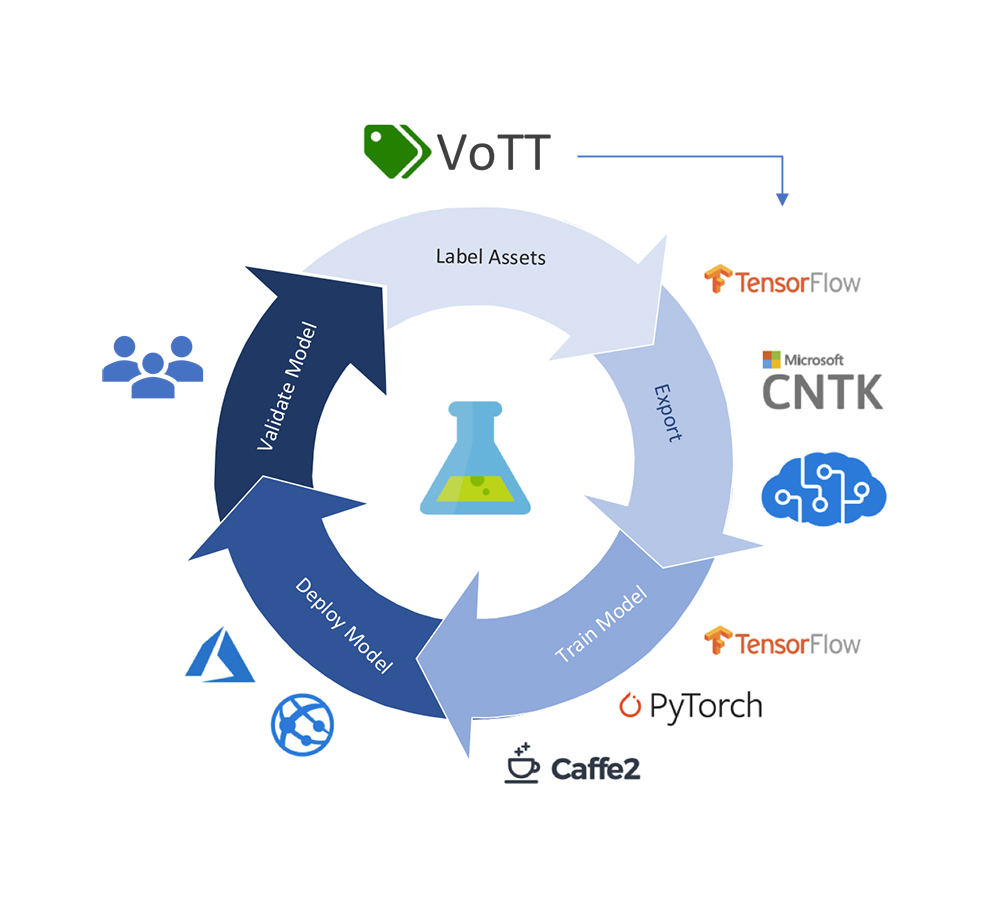
なにがすごいのか?
画像だけでなく映像にも応用できる
リアルタイムな画像認識・分類・検索
Windows, Mac, Linux問わずクロスプラットフォームで動作
深層学習フレームワークに対応した出力形式
学習済モデルでのアノテーションが可能
なぜ生まれたのか?
従来の画像認識や物体検出において、大量のメタデータ・タグ付きデータの生成という事務的作業が大きな手間となっていた。学習データベースの拡充や創造的な時間の確保といったニーズを受け、各種画像アノテーションソフトが開発されてきた。
なぜできるのか?
学習コーパス
大量の画像とラベルの対からなる学習用コーパス(*1)を用意。画像特徴とラベルの関連を学習させる。
(*1)コーパス:言語を分析するための基礎資料として、書き言葉や話し言葉の資料を体系的に収集し研究用の情報を付与したもの。
ラベル付与
入力画像を複数の領域に分割し、学習モデルを用いて各領域のラベル生成確率を計算。各領域の確率を統合した結果算出された画像全体のアノテーションスコアが閾値以上のモデルをラベルとして画像に付与。Camshift(*2)アルゴリズムによりトラッキング、アクティブラーニングが可能。
(*2)Camshift(Continuously Adaptive Meanshift):動画に写る物体を発見・追跡するための手法の一つ。ある画像と領域を与え、その領域を平行移動して画像に重ねたとき、領域内の輝度が極大になるところを探索するMeanshift法を拡張し、追跡対象の見え方によって領域のサイズを調節する手法。
相性のいい産業分野
- アート・エンターテインメント
映画やTV映像の各シーンに対する詳細な情報の付加による検索性の向上や広告連動
- 流通・モビリティ
運転中の車載カメラに写る対象物を「人」や「車」として特定、自動運転の学習データとして付与
- 医療・福祉
画像にタグ付けされたアノテーション情報を機械が発音することで、視覚障がい者が画像情報を理解するプロセスを半自動化
- IT・通信
電子商取引での商品リストの分類補助
この知財の情報・出典
この知財は様々な特許や要素技術が関連しています。
詳細な情報をお求めの場合は、お問い合わせください。