


News
2023.08.31
知財ニュース
東大松尾研究室、100億パラメータの日本語・英語大規模言語モデル「Weblab-10B」を公開─国内最高水準

東京大学大学院工学系研究科技術経営戦略学専攻松尾研究室は、日英2カ国語に対応した100億パラメーターの大規模言語モデル(LLM)「Weblab-10B」を公開した。
「Weblab-10B」は、日本語の精度向上を目的に開発された言語モデル。事前学習に英語のデータセット「The Pile」と日本語のデータセット「Japanese-mC4」を、事後学習に英語のデータセット「Alpaca」「Flan 2021」「Flan CoT」「Flan Dialog」と日本語訳のデータセット「Alpaca」を使用し、日本語と英語双方のデータセットを学習に用いることで、学習データ量の拡張を行っている。

近年の大規模言語モデルは、インターネットから収集された学習に使用するテキストデータの多くが英語などの一部の主要言語で構成され、日本語などのテキストデータの大量収集に限界があったという。そこで、同研究室は日本語と英語のデータセットを学習に用いた本モデルを開発。日本語と英語両方の言語を学習に使用し、言語間の知識転移を行うことで日本語の精度を高め、100億パラメータサイズの大規模言語モデル「Weblab-10B」を開発し公開に至った。
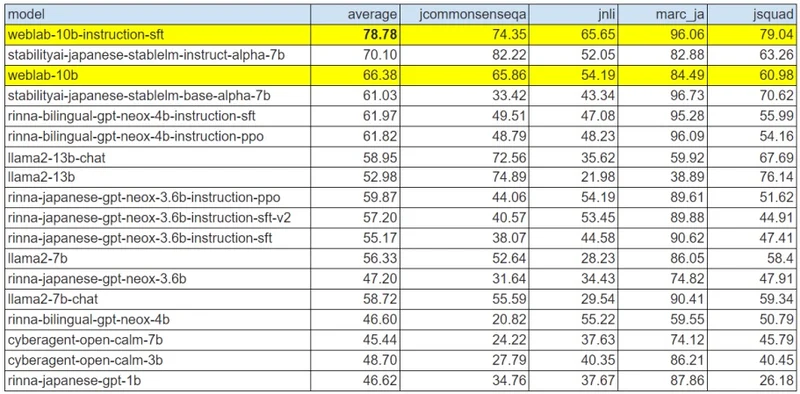
また、「Weblab-10B」では、事後学習(ファインチューニング)に英語のデータセット4つに対し日本語訳のデータセット1つと、事後学習の日本語データ比率が低いにも関わらず、JGLUE(日本語言語理解ベンチマーク)の評価値が事前学習時と比べて66%から78%に改善。同研究室は、これは国内の公開モデルでは最高水準のものとしている。
なお、「Weblab-10B」の事前学習済みモデルと、事後学習済みモデルは、「Hugging Face」からダウンロードが可能。いずれも商用利用は不可のモデルとして公開されている。
Top Image : © 東京大学大学院 工学系研究科