


News
2023.08.15
知財ニュース
Google DeepMind、Webとロボットから学びロボット制御するVLAモデル「RT-2」公開─事前トレーニングにないタスクでも動作

米Google傘下のGoogle DeepMindは米国時間7月28日、Webとロボットデータの両方から学習してロボットの動作指示に変換するAIモデル「RT-2(Robotic Transformer 2)」を公開した。
RT-2は、Web上のテキストや画像、ロボットの言語コマンド・カメラ画像・タスクアクションなどのデータを学習し、ロボットの行動を制御する、世界初の視覚-言語-行動(VLA:vision-language-action)モデルだ。事前にトレーニングしていない内容でも、Web学習などを通じてコマンドを解釈し、動作へ変換できる。
前身であるRT-1は、ロボットデータで学習した、ロボット動作指示を行うマルチタスクモデルだ。複雑なタスク遂行が可能な「Everyday Robots」を13台用い、オフィスキッチンで17カ月間稼働させて収集したデータでトレーニングしており、700以上のタスクを行える。
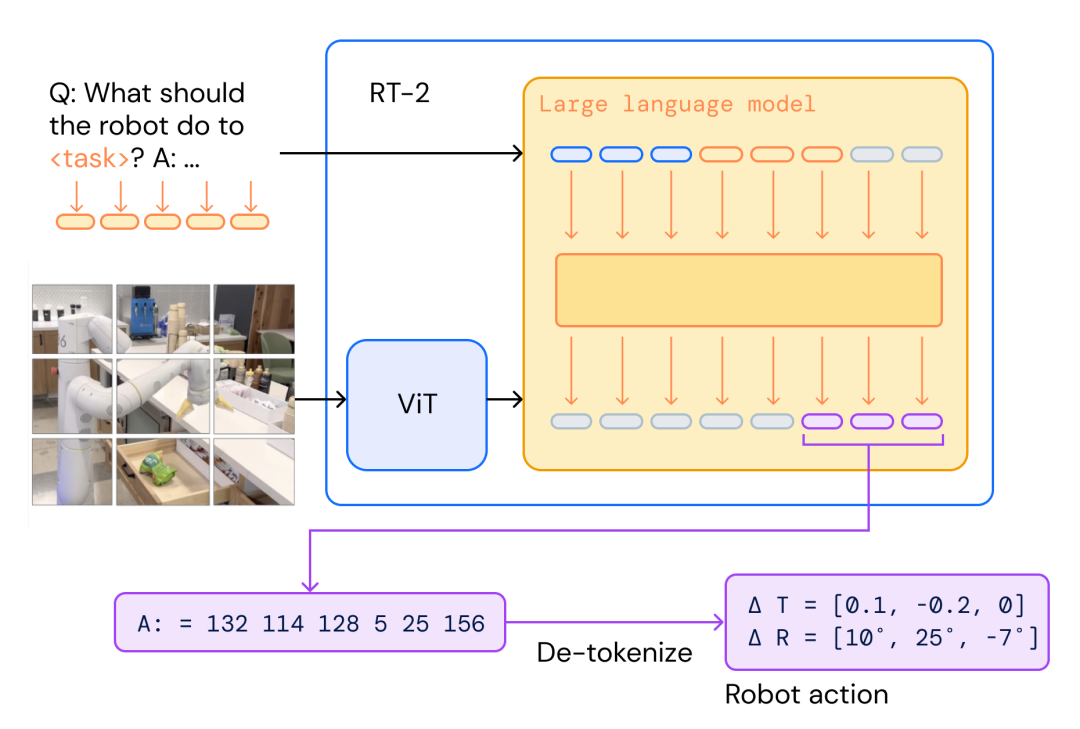
RT-2は、RT-1をベースに、テキストと画像を同じように扱える視覚言語モデル(VLM)を組み合わせて構築。Web上のデータで学習し物体認識や画像のキャプション付けなどが可能なVLMの中で、PaLM-Eと PaLI-Xを用いた。
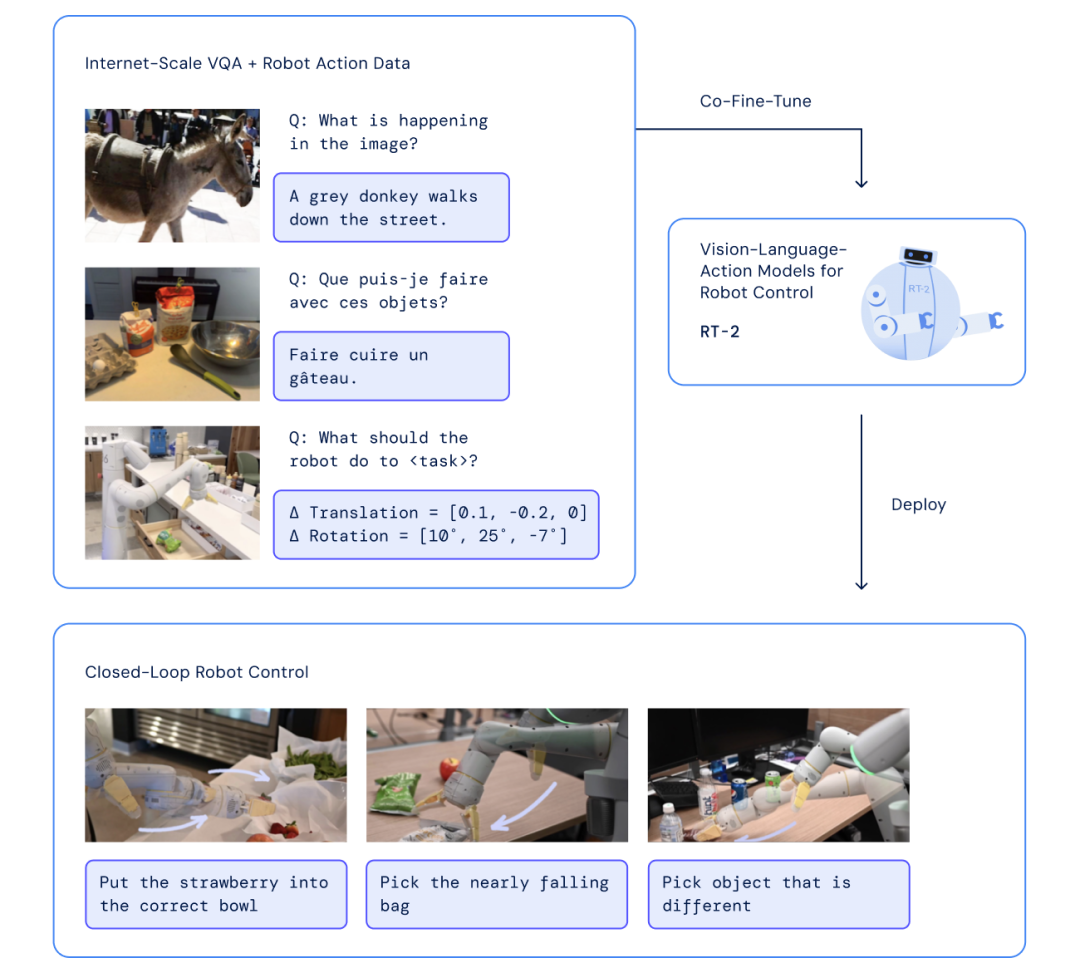
研究チームは、ロボットデータをVLMに適合させるため、ロボットの動作をテキストトークンとして文字列表現に変換。Webから得たデータセットと合わせて学習させ、チューニング・トレーニングを行ったという。
試行実験では、ロボットデータに含まれているタスクだけでなく、Webから学習した知識の活用が必要なタスクも要求。例えば、「イチゴを適切な器に入れる」「コーラの缶をテイラー・スウィフトの肖像の近くに動かす」など。概念を理解して、既存データにはないシナリオやモノに対する動作を行うタスク実験を行った。

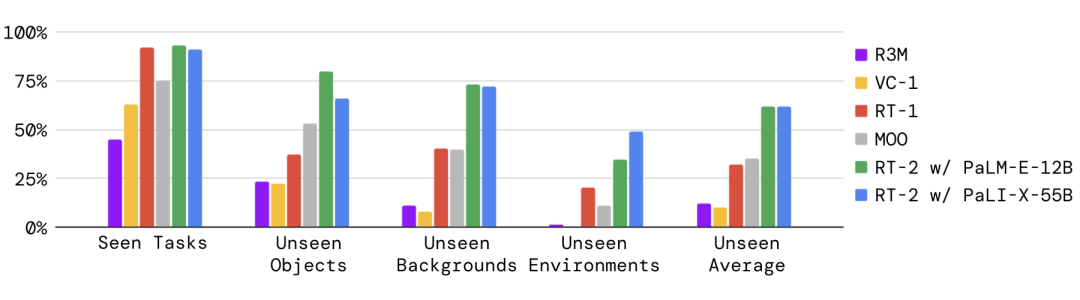
6,000回を超える実験を行った結果、RT-2は、既存タスクへの実行性能を保ちつつ、ロボットデータに含まれていないタスクの実行性能を大幅に向上させると確認。データ外タスクの実行性能では、RT-1が32%だったのに対して、62%にまで向上したという。
研究チームは、RT-2の開発にあたって、大規模言語モデル(LLM)に用いられている思考連鎖型プロンプトの手法にインスピレーションを得たと述べている。特に言語と行動を併用する能力を高めるために、数百の推論ステップの微調整を行ったという。
チームは本研究の目的を、インターネット規模の視覚言語データの学習をロボット制御に活かす単一モデルを構築することと位置付けている。今後の進展により、ロボットの実行範囲を拡げ、汎用性を飛躍的に高めると期待される。
「RT-2」GitHubページ
関連ブログ
論文 “RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control”
Top Image : © Google DeepMind