News
2024.01.28
知財ニュース
Stability AI、テキストや画像から動画を生成するAI「Stable Video Diffusion」を公開

画像生成AI(人工知能)企業のStability AIが、動画生成用モデル「Stable Video Diffusion」を公開した。今回公開されたモデルは画像モデル 「Stable Diffusion」 に基づく最初の基盤モデルとのことだ。

現在、研究プレビューとして、「Stable Video Diffusion」 のコードを GitHub リポジトリで公開しており、ローカルでモデルを実行するために必要なウェイトは Hugging Face のページで確認可能だ。モデルの技術的能力に関するさらなる詳細は、研究論文で確認できる。
このビデオモデルは、単一画像からのマルチビュー合成など、様々なタスクに簡単に適応させることができる。同社は「Stable Diffusion」をベースにして構築し、拡張する多様なモデルを計画しているという。
さらに、新しいウェブ体験へのアクセス待ちリストに登録することが可能となっている。このツールは、広告、教育、エンターテイメントなど、多数のセクターでの Stable Video Diffusion の実用的な応用を示しているとしている。
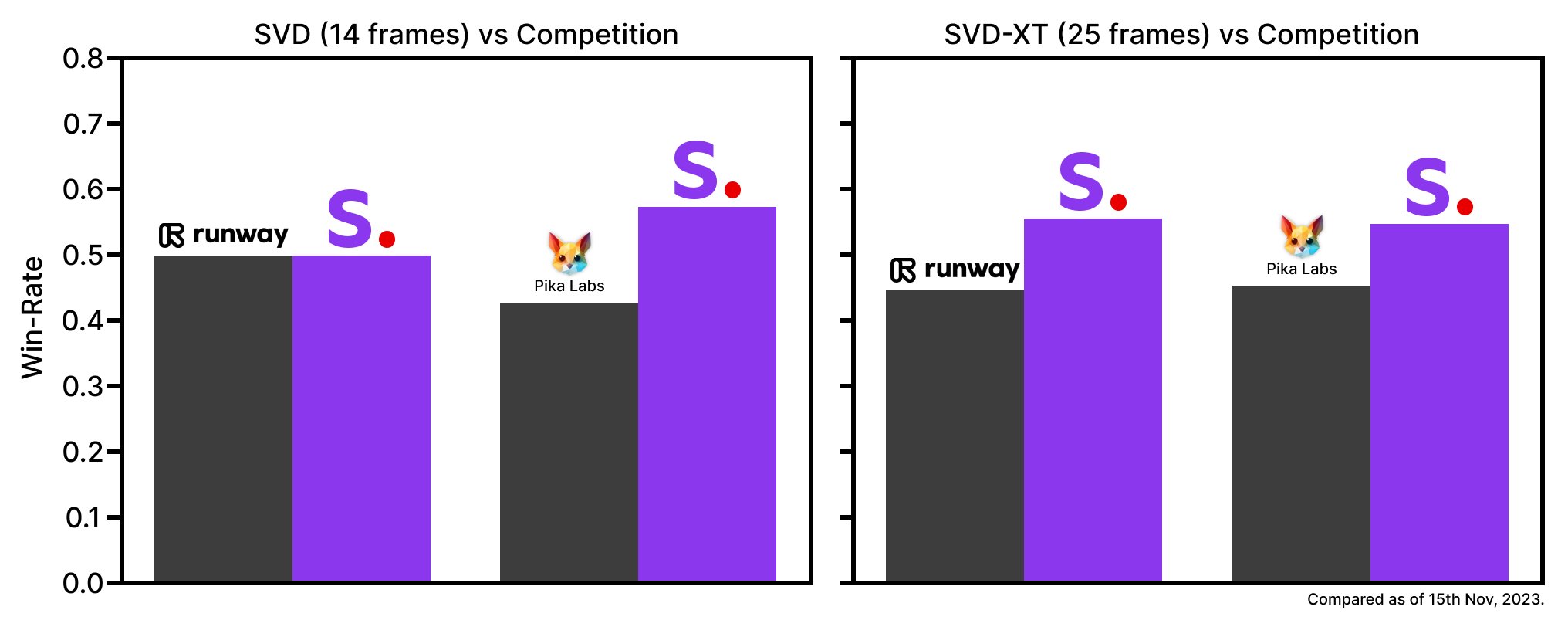
Stable Video Diffusion は、14フレームおよび25フレームを生成できる2種類の画像からビデオへのモデルとしてリリースされており、3~30フレーム/秒のカスタマイズ可能なフレームレートで生成が可能だ。基礎的な形でリリースされた時点での外部評価を通じて、これらのモデルがユーザーの好みの研究で先行するクローズドモデルを上回っていることがわかる。
最新の進歩に基づいてモデルを更新し、ユーザーのフィードバックを取り入れるているが、まだこの段階では実世界や商用アプリケーションでの使用は意図していないとのことだ。
Top Image : © Stability AI Japan 株式会社