

No.947
2024.11.26
多言語での音声生成や感情制御などが可能な音声クローン技術
OpenVoice

概要
「OpenVoice」とは、多言語の声の生成や、声のスタイルの制御が可能な音声クローン技術。数秒程度の短い発話音声で話者の声を複製して、元の言語だけでなく、多言語で音声の生成が可能。感情・アクセント・リズム・ポーズ・イントネーションといった、声のスタイルも細かく表現できる。2024年4月にリリースした「OpenVoice V2」では、英語、スペイン語、フランス語、中国語、韓国語、日本語に対応している。従来技術では、クロスリンガルの音声生成には、大規模な多言語話者のトレーニングデータ(MSMLデータセット)が必要だが、独自設計でそれを必要とせず、トレーニングされていない言語への対応も可能にしている。音声コンテンツ・メディアやアバター、コミュニケーションツールへの展開など、幅広い活用が期待される。
なぜできるのか?
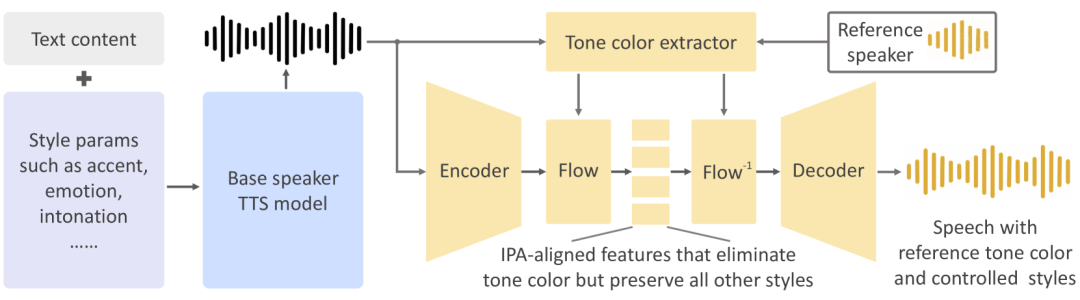
独自設計による音声の構成要素の分離
言語の生成と音声スタイルといった声の構成要素を、可能な限り切り離す独自設計を採用している。それぞれの要素が独立しているため、制御が容易で、流暢な音声を生成可能。計算効率も高いため、未知の言語にも対応できる。また、話者の声の感情やイントネーションといった、声のスタイルのデータを保持することが可能。話者の特徴を捉えた自然な声を生成する。システムには、言語と声のスタイルの制御を行う「Base Speaker TTS Model(ベーススピーカーTTSモデル)」と、声色を模倣して音声に適用する「Tone Color Converter(トーンカラーコンバーター)」を用いている。
柔軟性・拡張性を持たせた技術展開
「OpenVoice」は、研究者・開発者を対象に完全にオープンソースで提供している。MITライセンスにもとづき、無料で商用利用が可能。インスタント・ボイス・クローニングの技術進歩や研究を促すことを目指し、ソースコードなどを含めた一連の技術は、論文掲載やGitHubなどで広く公開している。また、言語と声のスタイルを制御する「Base Speaker TTS Model」には、機械学習による音声合成手法「VITS」を用いているが、安価な市販モデルなど、他モデルの利用も可能。柔軟性のある仕様にしている。
相性のいい産業分野
- AI
手軽で汎用性の高い音声クローニングツールの開発
- メディア・コミュニケーション
手間・コストをかけずに多言語でリアルタイム配信できるメディア・コンテンツの構築
- IT・通信
メタバースなどデジタル空間でアバター間のコミュニケーションに活用
- 教育・人材
言葉の壁なく学べる教育用ツールの開発
- 生活・文化
生前データをもとに、亡くなった著名人アバターに会えるコンテンツを提供
この知財の情報・出典
この知財は様々な特許や要素技術が関連しています。
詳細な情報をお求めの場合は、お問い合わせください。
Top Image : © MyShell