


News
2023.07.21
知財ニュース
NEC、世界トップクラスの日本語性能、130億パラメーターで軽量な大規模言語モデルを独自開発

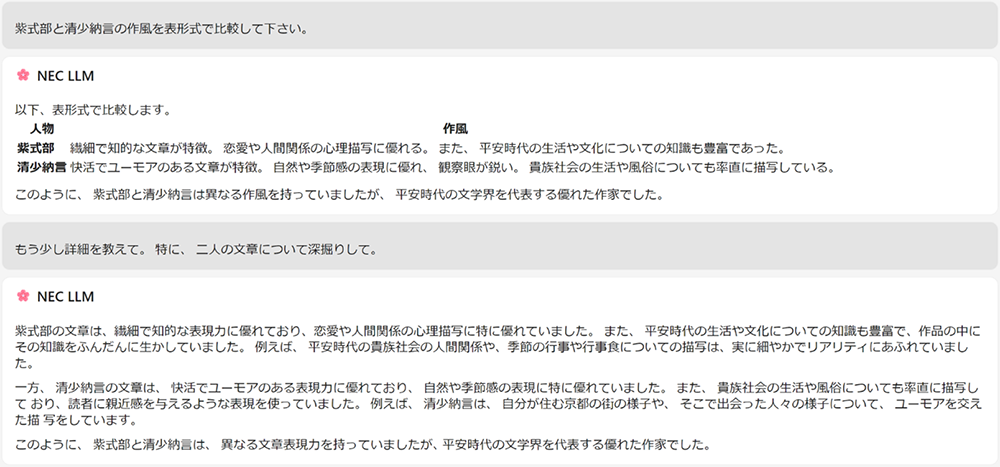
日本電気株式会社(NEC)は2023年7月6日、独自に収集・加工した多言語データを利用した日本語大規模言語モデル(LLM)を開発したと発表した。
本LLMは、高い性能と130億パラメーターというコンパクトさを両立した汎用的なファウンデーションモデル(基盤モデル)。GPU1枚搭載の標準的なサーバで動作でき、アプリケーションのレスポンスも向上できるほか、業務運用時の電力消費やサーバコストも抑えられる。

日本語における高い性能も特徴で、同社が日本語言語理解ベンチマーク「JGLUE」で評価したところ、知識量に相当する質問応答で81.1%、推論能力に相当する文書読解では84.3%と、世界トップレベルの性能を達成したという。

LLMの性能を示すパラメーター数は、数が大きくなると動作環境の要求も重くなる。そこで同社では、LLMの性能がパラメータサイズの他にも、学習に使われたデータ量と学習時間に左右されることに着目。パラメータサイズをGPU1枚で動作する範囲に抑えた上で、多量のデータと膨大な計算時間をかけることで、高い性能を実現した。
なお、本LLMは事前学習済みで、具体的な業務に対応したファインチューニングなどは行われていないファウンデーションモデル(基盤モデル)だが、業務に特化したLLMを短期間で容易に構築可能。ユーザーのオンプレミス環境でも動作できるため、秘匿性の高い業務にも安心して利用できる。
同社では、すでに同社で本LLMの活用を開始。文書作成や社内システム開発におけるソースコード作成業務など、様々な作業の効率化に貢献しているとのこと。
Top Image : © 日本電気 株式会社